-
Demand Prediction | Advanced Learning AlgorithmMachine Learning/Stanford ML Specialization 2023. 11. 14. 21:12
Logistic Regression을 다시 살펴보자.
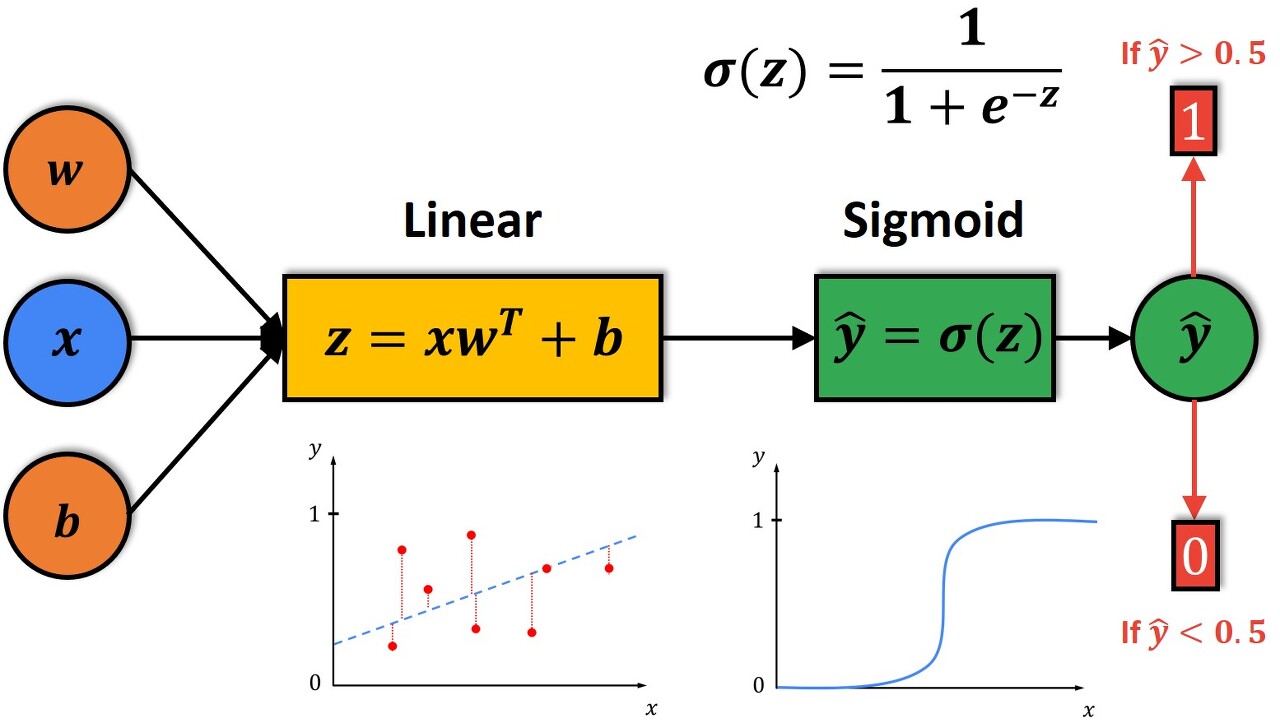
https://datahacker.rs/004-machine-learning-logistic-regression-model/ Sigmoid 함수를 이용해서 알맞은 z를 찾는데, 이 z는 w, x, 그리고 b를 이용해서 계산한다. 그리고 threashold(위 이미지에서는 0.5이다)를 정해서, 1이 될 확률 또는 0이 될 확률을 예측하는 알고리즘이다. 여기서 이 모델을 f(x)가 아닌 a라고도 하는데 이는 activation의 약자이고, 이것은 실제 뇌과학에서 뉴런이 신호를 보낼 때 쓰는 단어이다. 만약 이 모델이 티셔츠의 가격을 이용해서 top seller인지 아닌지 예측하는 알고리즘이라면, price라는 x, input을 모델, 즉 1개의 뉴런(sigmoid 함수이다)에 넣어서 top seller가 될 확률을 구해주는 연산을 한 후 output한다고 말할 수 있다. 이 예시는 1개의 뉴런이지만, 이런 일들을 여러 뉴런이 엮어서 같이한다면?
문제를 나눠서 생각해보자
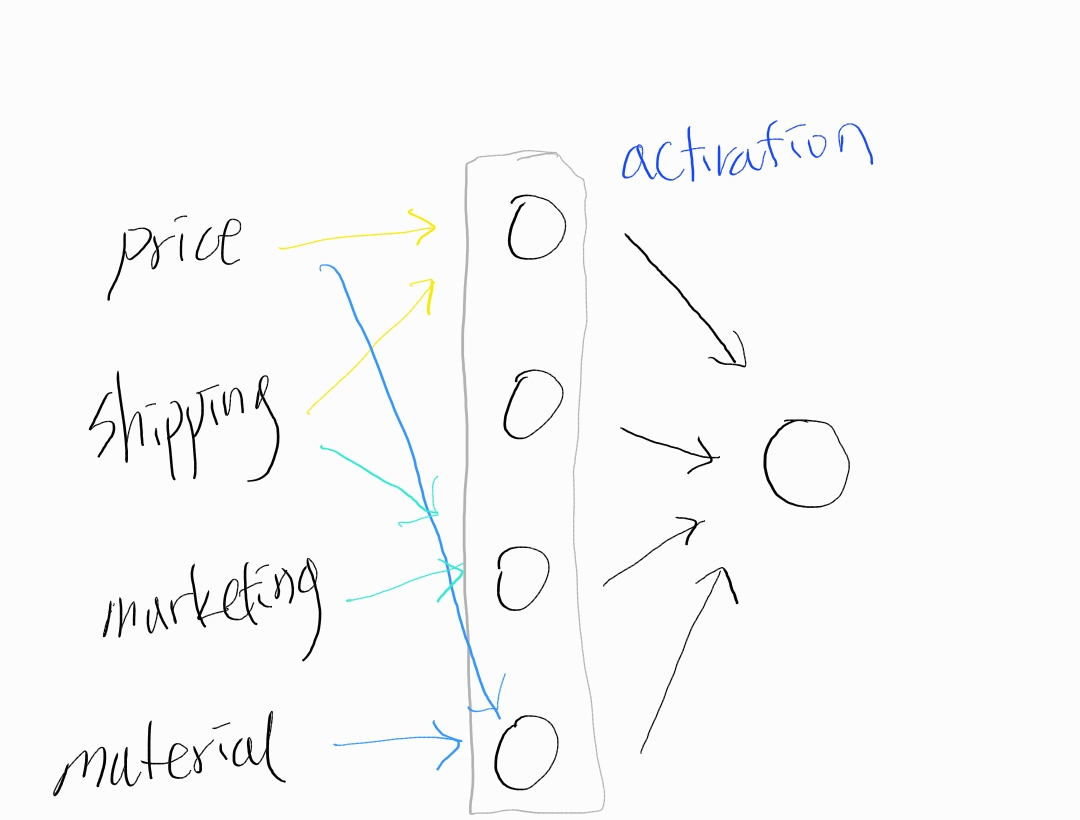
Neuron's Activation Top Seller가 될 수 있도록 만드는 요인은 여러가지가 있다. Affordability(여유, 형편), Awareness(인식) Perceived Quality(품질에 대한 인식)과 같은 요소가 있을 수 있다. 그렇다면, 그 하나하나의 값들을 계산할 때 필요한 인풋이 다를것이다. 먼저, Affodability의 경우, 가격(price)와 배송(shipping cost)등을 인풋으로 중간 모델을 만들 수 있다. 또 Awareness의 경우에는 다른 input 요소들이 필요할 수 있다. 이렇게 중간 단계에서 이러한 요인들을 계산한 후, 각 요인에 또다른 무게(weight)을 주어서 최종 모델을 계산하는 layer 방식으로 접근하면, 간단한 linear보다 좋은 효과를 낼 수도 있다.(항상 그러는것은 아니다) 위에서는 인풋 갯수를 4개만 그렸지만, 약 10개가 되는 숫자를 4개정도로 줄이고, 그 3개의 숫자를 1개로 줄여서 신경망을 만들 수 있다.
위와같은 경우에는 우리가 사용하는 Input 갯수가 10개 내외이기 떄문에, 각 요인에 대한 것들을 하나하나 직접 연결을 해주었다. 하지만 만약 Input이 수백, 수천, 또는 그보다도 많다면? 수작업으로 하기에는 너무 많은 시간과 인력이 필요하다. 그 점을 보완해서 입력 계층의 모든 층에 접근할 수 있도록 모든 요소와 모든 인풋을 계산하면, 그런 수고스러움을 피할 수 있다. 그렇게 되면 모든 입력값은 모든 중간 layer의 뉴런들에 모두 접근하게 된다.

Neural Network 여기서 price, shipping, marketing, material등을 input layer라고 하고 벡터 x라고 표기한다. 또한 중간의 layer는 1개의 층이 아니라 몇개의 층도 더 될 수 있다. 또한 마지막 한개의 뉴런을 output layer라고 하며, 중간에 있는(이 예시에서는 1개의 계층이지만) 계층들을 hidden layer(s)라고 한다.

hidden and output layer hidden과 output layer의 관계를 보면, 어쨌듯 이미 계산된 세개의 값들을 갖고 sigmoid함수를 이용해 top seller가 되는지 아닌지를 알아내는 logistic regression일 뿐이다. 하지만 중간에 hidden layer를 이용해서 컴퓨터가 한번 더 생각할 계층을 만들어주는 방법이다.
Feature Engineering에 대해서 다시 짚어보자. 집값 예측을 할 때, 집의 가로, 세로 길이를 알고있을 때, Feature Engineering을 통해서 집의 넓이를 임의로 계산해 size라는 column을 추가해서 계산하는 engineering 수동 기법에 대해서 이야기 했었다. 하지만, 신경망(Neural Network)기법을 이용하게 되면, 이런 수동 설계가 필요 없이, 스스로 특성을 학습하여서 모델을 만들게 되기 때문에, 오늘날 가장 강력한 알고리즘이 되었다. 이 신경망(NeuralNetwork)의 정말 좋은 특성중 하나는, 신경망을 트레이닝 시킬 때, 위에서 처럼 afforadability, awareness, quality등의 Feature들이 무엇인지 명시적으로 결정해서 지정할 필요가 없다는 것이다. 이런 작업은 Neural Network가 대신 계산하게 된다. 이게 바로 Neural Network가 강력한 이유이다.
하지만, 이 모델을 만드는 엔지니어가 한가지 결정할것이 있다. 바로 몇개의 Hidden Layer를 만들것인지, 그리고 각 Layer마다 몇개의 Neuron들을 생성할것인지 이다. 이는 Neuron Network Architecture 분야의 숙제이다. 이는 모델 성능에 큰 영향을 끼친다.ㅇ
6-6-8 로 설계한 예시 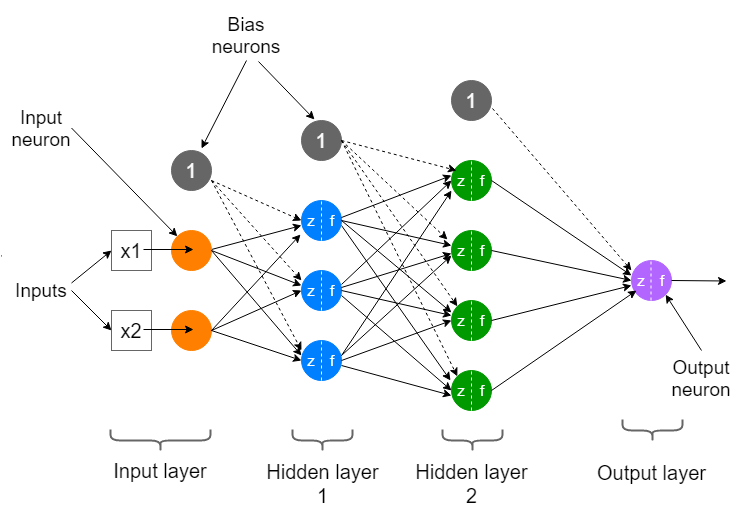
3-4 로 설계한 예시 Reference
Advanced Learning Algorithms
In the second course of the Machine Learning Specialization, you will: • Build and train a neural network with TensorFlow to perform multi-class ... 무료로 등록하십시오.
www.coursera.org
https://datahacker.rs/004-machine-learning-logistic-regression-model/
#004 Machine Learning - Logistic Regression Models - Master Data Science 25.07.2022
Master Data Science - Datahacker. Here we have provided high-quality information for you to get started with data science ...
datahacker.rs
Two or More Hidden Layers (Deep) Neural Network Architecture
Neural Networks and Deep Learning Course: Part 3
medium.com
https://www.researchgate.net/figure/Deep-Neural-Network-with-multiple-hidden-layers_fig1_343150201
'Machine Learning > Stanford ML Specialization' 카테고리의 다른 글