-
The Problem of Overfitting (과적합 문제) | Supervised Machine Learning: Regression and ClassificationMachine Learning/Stanford ML Specialization 2023. 11. 6. 22:02
골디락스와 곰 세마리
골디락스와 곰 세마리라는 동화가 있다. 골디락스는 어쩌다가 곰의 집에 들어가게 되는데, 그 집에는 모든 물건이 세개씩 있었다. 아빠곰을 위한 가장 큰 것, 엄마곰을 위한 중간 사이즈, 그리고 아기 곰을 위한 작은것, 모든게 세가지였다. 골디락스가 스프를 먹을 때, 첫번째 큰 그릇의 스프는 엄청 뜨거웠고, 두번째 중간사이즈 스프는 차가웠고, 마지막 그릇에 있는것은 딱 적당~ 하게 좋았다.
https://youtu.be/QvnGq8wrj9E?t=250
Overfitting과 Underfitting
Linear Regression
자, 그럼 Overfitting과 Underfitting에 대해 알아보자. 위의 골디락스 이야기는 앤드류응 교수님께서 수업시간동안, Overfitting, Underfitting을 설명해주시기 위해 언급한 내용이었다. 머신 러닝도 마찬가지다. 아래 Linear Regression의 예시를 보자.
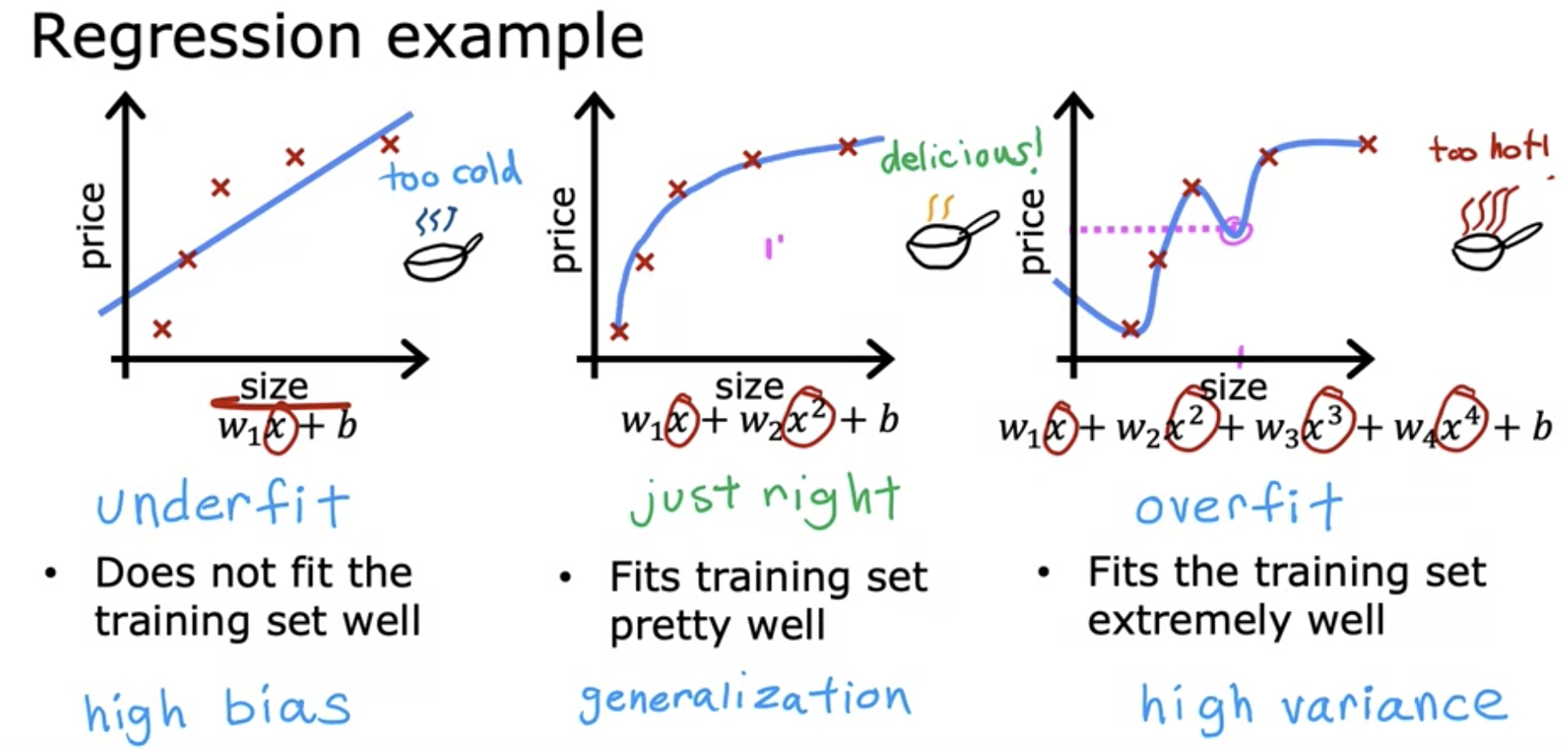
https://youtu.be/8upNQi-40Q8 1차 방정식을 이용해서 집값을 예측하게 되면, 계산은 간단하지만 맞지않는 값이 많아지게 된다. 즉, Underfitting이라고 할 수 있다. 2차 다항식을 썼을때는, 상당히 많은 가격을 예측할 수 있었다. 딱! 좋은 온도의 골디락스가 먹은 스프처럼 모델이 트레이닝 셋들과 꽤 잘 들어맞게 된다.
하지만 만약, 욕심을 내서 4차 다항식을 이용했다면? 4차를 사용했으니 무조건 좋을까? 정답은 "아니다" 이다. 그리고 이런것을 Overfitting이라고 한다. 오른쪽 위의 그래프를 보면 알겠지만, 4차 다항식을 써서 모든 값을 하나하나 다 정확하게 맞추려고 하다가, 실제 전체적인 흐름에서 벗어나는 그래프가 생성되어서, 결국엔 예측률이 현저하게 떨어지는 결과를 줄 수 있다. 4차 다항식 알고리즘의 분산이 매우 크기 때문이다.
모델을 생성할 때, 중간의 예시처럼 generalization(일반화)하는것이 중요하다. 즉, 이전에 본 적이 없는 새로운 데이터에 대해서도 잘 작동하는 능력을 갖도록, 훈련 데이터에 지나치게 맞추지 않고 새로운 데이터에 대해서도 유용한 예측을 할 수 있도록 설계하는 것이 중요하다.
Classification
Classification에서도 마찬가지이다. 알맞은 다차항의 함수를 이용해서 generalization을 잘 해주는것이 중요하고, 너무 모든 데이터를 지나치게 맞추지 않도록 유도하는것이 중요하다.

https://youtu.be/8upNQi-40Q8 Reference
'Machine Learning > Stanford ML Specialization' 카테고리의 다른 글